

Weet jij nog hoe de eerste website van HCC in 1996 eruitzag? De Wayback Machine wel: deze online bibliotheek archiveert websites, helemaal tot aan het begin van internet. Zij bevat inmiddels miljarden versies van opgeslagen webpagina’s en is voor iedereen toegankelijk.
De Wayback Machine is onderdeel van Internet Archive, een non-profitorganisatie in San Francisco in de VS. De ambitieuze missie van deze organisatie is “universele toegang bieden tot alle kennis”. De digitale archieven van Internet Archive bevatten zo’n 20 miljoen boeken, 10 miljoen video- en audio-opnamen, 3 miljoen beelden en 200.000 softwareprogramma’s en vooral talloze website-versies.
Volgens de laatste schatting bestaan er op het wereldwijde web zo’n 1,75 miljard unieke domeinnamen. Die websites zijn voortdurend in ontwikkeling. Onderdelen komen erbij of vallen af, huisstijlen en functionaliteiten veranderen, bedrijven gaan failliet en halen hun site offline. Van al die websites bestaan dus oudere varianten die ofwel door hun eigenaren (particulieren, bedrijven of overheden) zijn bewaard of die onbeheerd rondzwerven op internet. Als je al deze opgeslagen versies, al deze momentopnamen, bij elkaar optelt, kom je tot een duizelingwekkende hoeveelheid van 446 miljard webpagina’s die op dit moment hun weg hebben gevonden naar het Internet Archive.
Webcrawlers
Iedereen die zijn site voor de eeuwigheid wil bewaren, kan zijn URL uploaden op de website https://archive.org/web. De enige voorwaarde is dat de site toegankelijk is voor webcrawlers, oftewel spiders. Dit zijn internetbots, programmaatjes, die voortdurend het wereldwijde web doorzoeken en kopieën opslaan van gevonden openbare webpagina’s. Dat klinkt dreigend, maar het is heel nuttig werk. De crawlers zorgen ervoor dat het internet netjes geïndexeerd blijft en dat zoekmachines ook daadwerkelijk resultaten opleveren. Maar dus ook dat sites worden opgeslagen in het Internet Archive.
Tijdmachine
De Wayback Machine is de zoekmachine voor deze internetgeschiedenis. Wil je bijvoorbeeld weten hoe de HCC-site zich door de jaren heen heeft ontwikkeld? Tik in de zoekbalk op https://archive.org/web simpelweg 'hcc.nl' in en klik op Browse history. Je ziet vervolgens een tijdbalk vanaf de eerste versie van de website tot nu. Selecteer een jaartal en er verschijnt een kalender waarop sommige data in blauwe rondjes staan. Op al die data is een snapshot, een momentopname, van de website gemaakt. Klik erop en je krijgt de website van dat moment op je scherm. Zo zie je dat de eerste gearchiveerde HCC-website (23 december 1996) Netscape 2.0 en Microsoft Explorer 3.0 ondersteunde, het klinkt inmiddels haast prehistorisch.

In de Wayback Machine staan niet alleen werkende sites, maar ook kopieën van websites die allang uit de lucht zijn. Bijvoorbeeld Hyves, wie kent hem nog? In 2004 zag deze Nederlandse concurrent van Facebook het licht en zo zag dat eruit: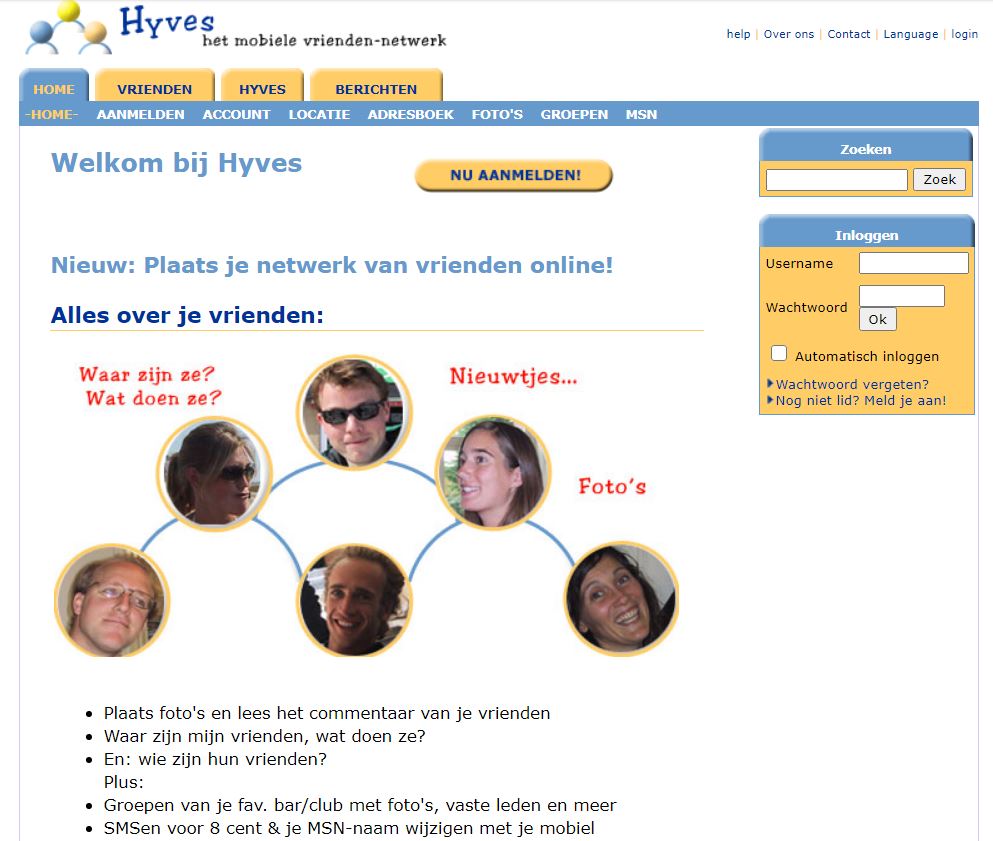
De Wayback Machine is voer voor de archeologen van de toekomst en een enorm leuke excursie voor iedereen die geïnteresseerd is in de nog maar korte geschiedenis van internet.




